挖掘物理世界中的智能

谢幸 微软亚洲研究院
引言
20世纪80年代末,当马克·维瑟(Mark Weiser)在施乐实验室提出普适计算的概念时,他绝对有着超前的预见性。马克·维瑟预测:未来计算机将逐渐从人们的视线中消失,和环境和谐地融为一体。
当时施乐实验室定义了三种普适计算设备,分别被称作ParcTab,ParcPad和Live Board。这三种设备的主要区别在于它们的尺寸:ParcTab被定义为厘米级设备,可以很方便地携带和移动,并具有网络连接和定位功能;ParcPad是分米级设备,大小和一张A4纸相当,可以移动但并不方便长期随身携带;LiveBoard则是米级设备,一般安放在固定的位置,可以支持多人共享使用。施乐实验室针对这三种不同类型设备的研究带动了一系列普适计算核心技术的发展,例如无线网络、定位技术、嵌入式系统、移动用户交互和传感器技术等。直到20多年后的今天,如果我们环顾四周,所看到的电子设备仍然可以归入这三类。2009年微软公司提出了三屏一云的战略,其中三屏指的是手机、电脑和电视,这正和马克·维瑟当初的设想遥相呼应。
近年来云计算技术的发展受到了广泛的关注。
和普适计算类似的是,云计算也试图改变计算的模式。它们的不同之处在于,普适计算让计算集成并隐藏在日常生活中,人们可以随时随地获取和处理信息;云计算则让计算、信息和应用等各种资源隐藏在互联网中,变为基础设施,人们可以像使用电能一样以即插即用的方式使用这些资源。普适计算主要强调终端设备和交互方式的变革,而云计算强调的则更多是服务和系统平台的变革。尽管有这些区别,这两种计算模式正在发生融合,也带来了很多新的机会。例如,最近提出的FourSquare技术,通过互联网连接用户的移动设备,感知用户的地理位置并让用户方便地共享各自的位置信息,从而提供创新的社交网络功能。FourSquare从创立到达到一百万用户,只花了短短一年时间,比Twitter快了一倍。我们相信在不远的未来所有普适计算设备不仅可以局域连接,还可以通过云平台扩展其功能并进行全局互联。
作为典型的普适计算设备,智能手机在过去的几十年里的发展也极为迅速。今年第二季度智能手机在整个手机市场的占有率已经接近20%。在几年前,微软研究院曾进行过一个MyLifeBits项目。
研究人员设计了专用的设备SenseCam相机用来长期收集人们日常生活中的照片和传感器数据,以期构建一个能反映人生经历的数据库。如今SenseCam的功能已基本可以被智能手机所替代。手机的功能从最初的语音通信发展到照相、收发邮件、网页浏览、游戏和社交网络,其能力已经接近传统的电脑。而在利用传感器技术方面,手机甚至超过了电脑。按照施乐实验室的定义,手机属于厘米级设备,适合用户长期随身携带。通过集成各种类型的传感器,例如GPS、指南针、加速度仪、温度计、环境光传感器等,手机可以更加深入地了解用户的状态,从而分析用户的兴趣,提供更为智能的用户交互方式。
这实际上和普适计算中的一个关键概念——情境感知极为相似。在普适计算领域,情境感知指的是移动设备通过感知环境变化,获取并理解情境信息,然后调整自身行为的过程。如果换个角度来看,移动设备就好像具有了智能,不再像传统电脑一样完全受人控制。智能手机和传感器技术的普及将对普适计算的发展产生重要影响。实际上我们可以将智能手机通过移动互联网构成的网络看作是一类特殊的、不需要事先部署的传感器网络。我们应该研究如何利用这个网络来感知物理世界,获取知识,并帮助开发更多的应用。近期美国加州大学洛杉矶分校(UCLA)的研究人员提出的参与感知模式(Participatory Sensing)和这个想法非常接近。参与感知模式试图利用人们日常使用的电子产品搜集数据,以进行一些特定的研究,例如环境污染、道路状况和群体行为模式等(关于参与感知模式的详细介绍可参见本期专题中朱浩华教授等撰写的《普适计算如何融入日常生活》一文)。相对我们的观点,参与感知模式最大的区别是其主动参与性,在他们的模式下,用户是通过主动参与来提供数据帮助研究,而我们希望用户只需要以被动的方式参与,即用户不需要为了数据采集而专门使用某项服务或设备,而是在日常生活中不知不觉地提供数据。例如,用户在移动设备上使用位置服务,或是在FourSquare中共享地理位置信息时,其实都在不知不觉地将他当时的位置共享给服务提供者,在用户允许的前提下,可以分析这些数据以了解人们在物理世界中的整体分布情况以及移动模式,这些知识对很多其他互联网应用,例如广告、旅游和购物的推荐都将产生帮助。
总而言之,我们试图通过这种自然的方式长期收集来自大量用户和大量设备的情境信息,从中挖掘智能,以更好的感知物理世界,从而帮助其他互联网应用提供更好的服务。当然,在获取到来自物理世界的知识后,为了能让它被更广泛地应用,还需要将它们与互联网上的知识相结合,并定义统一的用户标识和统一的知识表示方法。在下一节,将具体介绍在这个方向展开的研究工作。
研究项目
通过使用不同的传感器,可以收集到不同类型的情境信息,例如用户位置、用户行为、环境信息(温度、湿度、光线、图像、音频)等。该研究最终选择了从用户位置作为出发点进行研究,一方面是因为室内外定位技术在近年来取得了长足进步。英特尔实验室的PlaceLab是这个领域知名的项目。他们提出使用GSM基站、蓝牙和Wi-Fi信息来进行低能耗的定位。目前这项技术已经在许多商业服务中被使用。另一方面,位置服务是有着巨大市场潜力的领域。有报道称在2013年位置服务将达到130亿美元的市场规模。关于位置服务领域的重要性和研究现状,可参见本刊2010年第6期的专题。
该研究项目的规划从2007年初开始进行,当时的主要困难就是缺乏数据。以往的工作往往是在小规模数据集或是模拟数据集上进行研究,但这样的研究结果通常无法推广或是缺乏可信度。为了解决这个问题,首先开始自己的数据采集计划。将GPS手机和GPS记录仪分发给学生、同事和朋友,通过两年多时间和160多人的参与,共收集到超过20万km的轨迹数据。目前该数据集已经共享在网站上1。
在这个数据集基础上,通过分析个人轨迹数据,挖掘用户的日常行为模式、社会关系、和旅游线路特征,具体研究结果可参见文献[2]。
与此同时,还尝试从微软产品日志和互联网上获取数据。当然,在2007年,互联网上还没有完全符合要求的服务出现,只能找到一些近似符合要求的数据。例如获取到100万条微软地图上的查询记录,每条记录都包含查询词和地图上的地理位置。
可以假设这个地图位置就是未来移动用户进行位置搜索时所在的位置,这样这个数据集就接近未来的移动用户搜索日志。在这个数据集上研究查询词与用户位置之间的联系,结果参见文献[1]。另外还从互联网上获取了大量带有地理标注的照片,它们可以看作是未来用户通过移动设备获取的来自物理世界的图像信息。在这个图像数据集上进行的工作将在下面两节中详细介绍。
城市地标挖掘[4]
在2009年Flickr就宣称已经拥有超过1亿张标注过的地理照片,而且这个数字还在迅速增长当中。
我们知道,用户在照相时并不是随机地按下快门,每张照片实际上都代表了一定的用户喜好,比如用户希望在这里留下纪念,或是看到了一些优美的风景。因而,这些照片其实反映了很多物理世界的知识,比如可以从照片中发现一座城市的地标性景点、用户经常选择的旅游路线等。这些知识对旅游业等非常有帮助。
在这个项目刚开始时,假设照片并没有标注准确的经纬度信息,而只是知道它们所在的城市。这个假设在当时还是符合实际情况的,因为具有定位功能的移动设备并不普及,大部分时候用户只愿意给照片标注城市名称,而不愿意在地图上准确地指定他们的拍摄位置。或因为当时身处陌生的城市,用户事后也无法回忆起准确的地点。
为了对算法进行评价,我们从Windows LiveSpaces上抓取了来自20个城市的38万张照片,这些照片都标注了拍摄地点(所在的城市)、拍摄时间、作者和文本标签。图1显示了数据集中来自巴黎并带有“卢浮宫”标签的部分照片。

从图1可以看出,在很多照片中都出现了卢浮宫前的玻璃金字塔入口,对于这样的地标性景点,旅游者通常会从几个固定的视角拍摄大量照片。这些照片的内容看起来一般都非常接近。这就可以直观地把照片组织成三个层次:第一层是城市,例如巴黎;第二层是景点,例如卢浮宫;第三层是场景,也就是景点里的某个特定视角,在这个例子里是玻璃金字塔。每个城市包含多个景点,每个景点也包含多个场景,代表不同的视角。我们的工作就是试图将这些照片结构化地组织成场景—景点—城市的关系,并找出这个城市在旅游者心目中最有代表性的景点。
在算法中,首先针对一个城市把所有的照片搜集起来,然后使用一种基于视觉和文本的层次性聚类算法创建这组照片的场景—景点图模型。在图模型上,算法分为两步:(1)为了在景点中发现具有代表性的场景,使用了类似于PageRank的算法——PhotoRank算法,在引入了文本和视觉链接关系的图上对照片的重要性进行迭代计算;(2)为了找到城市中的地标性景点,使用Landmark-HITS算法,此算法综合考虑了作者、景点和场景之间的相互影响。
下面来具体介绍这两步的细节。
生成场景—景点图模型
首先对数据集中的所有照片抽取出SIFT局部特征[5]。然后将这些SIFT特征层次聚类量化为词汇树[6]。通过查找词汇树,每张照片被表示为一个Bag-of-Visual-Words向量,向量中每个Visual Word的权重使用了TF-IDF方法来计算。两张图片对应向量之间的余弦距离定义为它们的内容相似度。
对于单张照片,提取它们的标题、相册标题、描述、以及评论中的文本信息。类似地,将每张照片的文本信息表示为一个向量,向量之间的余弦距离可以看成是照片之间的文本相似度。
定义了内容相似度和文本相似度以后,先针对照片的视觉内容进行聚类,找出视觉接近的照片组,也就是场景。为了滤去噪声,过滤掉包含极少照片的冷门场景以及缺乏文本描述的场景。
在每个场景内,将所有的文本描述合并,生成一个统一的Bag-of-Words向量来描述整个场景。最后对这个文本向量进行聚类,将场景进一步组织成景点。为了提高文本聚类的准确性,去除了文本中的停止词,形容词,动词以及所在城市名称。
发现地标性景点
在生成场景-景点结构后,为每个景点创建相应的景点图。
景点图中的结点代表该景点中的所有照片,而边的权重代表两张照片之间的内容和文本相似度。
在这张图上使用了一种类似于PageRank的PhotoRank算法来计算每张照片的重要性。
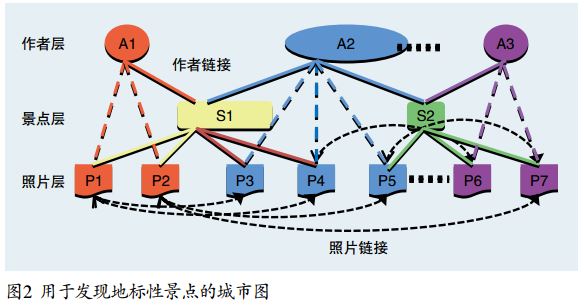
最后,为每个城市建立城市图。如图2所示,城市图分为三层:照片层、景点层、和作者层。照片层中的结点代表这个城市中的所有照片,照片的重要性可以通过前一小节中介绍的方法计算。景点层中的结点代表城市中的所有景点,需要计算它们的代表性。作者层中的结点代表所有在该城市拍过照片的旅游者,每个结点都具有一个权威性属性。图中的照片链接体现了景点图中照片之间的联系,而作者链接用于作者权威性和景点重要性之间的迭代计算。

将作者结点看为是HITS算法[7]中的Hub结点,而景点和照片结点看成是HITS算法中的Authority结点,然后在这个城市图上通过改进的HITS算法Landmark-HITS来得到所有景点的重要性和作者的权威性取值。最后所有重要性超过一定阈值的景点即输出为地标性景点。图3显示了利用该算法在悉尼、北京和罗马的城市图上发现的地标性景点。
个人旅行路线模式挖掘[3]
在前面的工作中,通过分析大规模带有地理标注的照片来发现城市中的标志性景点。随后,我们希望能进一步了解每一个人的旅行规律,这对旅游应用将会带来更大的帮助。由于假设照片都带有作者、时间和地点信息,可以从数据中恢复出用户当时的旅行路线,包括经过的地点、停留时间以及文本描述。从这些信息中我们可以猜测出用户旅行的目的,例如商务、观光、美食或是其他活动。可以针对不同的旅行目的从数据集中找出那些频繁出现的路线,它们往往代表了旅行者的实际选择和经验,为未来的旅行提供有益的参考。
在这次项目中,从Flickr获取了一个规模更大的数据集,包括570万张地理标注过的照片和5240万个文本标签,它们来自近3万名Flickr用户。设计的算法可以自动的将照片分割为不同的旅行路线,并识别出每条路线的旅行目的,最后针对每个旅行目的找出那些频繁出现的路线。
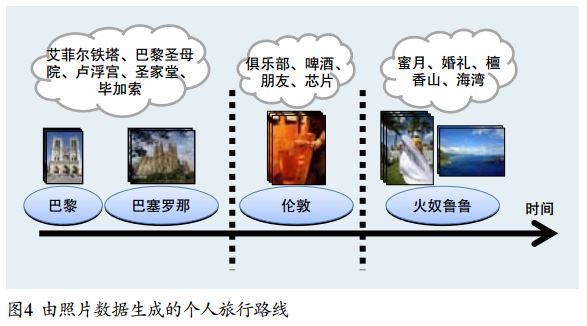
图4显示了从某个用户照片数据中生成的部分旅行路线,包括一条前往巴黎和巴塞罗那访问历史名胜的路线,一条在伦敦会见朋友的路线,和一条去夏威夷度蜜月的路线。
旅行路线分割
考虑到用户一般不会手工将照片按旅行路线分割后再上传到网站,因此需要对数据集进行分割,以得到实际的用户旅行路线。这通常也被称为照片事件检测。传统的照片事件检测算法一般只考虑拍摄时间的间隔,不考虑它们的拍摄地点。当然这主要是由于技术的限制,因为以往的照片很少带有地点信息。
在文献[8]中,普拉特(Platt)等人定义了照片拍摄时间的显著间隔概念,用来分割照片数据。具体地说,是将当前的拍摄时间间隔与附近的平均间隔比较,如果间隔明显增大则认为当前的时间间隔是一个事件的分割点。
在对数据进行观察后发现,拍摄地点的更换往往直接反映了用户的活动,可以帮助提高事件检测的准确性。另外,由于用户经常对同一事件中拍摄的照片使用类似的文本标签,因此照片的文本标签也具有一定的辅助意义。基于以上原因,在算法中同时使用拍摄时间、拍摄地点和文本标签信息。
将文本标签的距离定义为:相邻两张照片中相同标签的数目除以前一张照片中标签的数目。如果两张照片都没有标签的话,则差异定义为0.5。
这里不使用传统的文本特征向量来计算标签差异,因为这样会对标签数目较少的照片不公平。在数据中,即使是同一个用户拍摄的照片,它们的标签数目也常常会有很大不同。例如,一张照片的标签是{birthday, party},而接下来的照片的标签是{birthday, party, Tom, Brenda, cake, Bill}。直观地看,这两张照片应该被归入同一事件,但如果使用全局的文本特征向量的话,它们的距离会非常大。
在实验中发现,如果只考虑时间间隔,算法会倾向于过度分割,也就是说将数据集分成了大量很短的旅行路线。而如果只考虑空间间隔的话,算法则会倾向于找到过长的旅行路线,很多不同路线会被合成。当同时考虑时间和距离时,算法则可以达到平衡。另外,通过观察发现只考虑文本标签的算法性能非常低,因为标签一般都很稀疏而且噪声比较大,但是如果将标签距离和时间空间距离相结合则可以进一步提高算法的结果。
旅行路线分类
在做完照片数据分割后,可根据旅行路线的目的对它们进行分类。在未来的应用中,用户便可以根据实际需求来查找推荐的路线,因为针对不同的旅行目的,推荐的路线和描述往往是有差异的。
在调研了相关的旅行网站、论坛和博客后,将个人旅行分为以下六种目的:历史名胜 参观著名的历史文化景点和世界遗产,例如卢浮宫,长城等。
自然风光 游览风景优美的自然景点,例如国家公园,尼亚加拉大瀑布等。
美食 以尝试当地的美食为旅行的目,例如去意大利品尝匹萨。
事件活动 旅行的目的在于参加特定的活动,例如婚礼等。
商务 旅行的目的是参加商务会议,大型活动等。
本地 在居住地附近作短期的旅行,例如会见朋友,家庭聚会等。
实际上,访问同一个地点的路线也可能会归属于不同的旅行目的。例如有些人去纽约是参观自由女神像,而另一些人则可能是参加会议。另外,算法只将路线归入一种旅行目的,但实际生活中用户的旅行有可能同时具有多个目的。例如用户可以去罗马参观古罗马斗兽场,同时品尝当地的匹萨,或是在硅谷开完会后去参观金门大桥。考虑这种多目的旅行是今后要考虑的研究方向。
由人工标注随机选取的6000条旅行路线作为训练和测试集,然后使用支持向量机算法进行分类。
在算法中,使用的特征包括以下几类:空间特征 旅行路线经过的城市。
时间特征 月份,星期,所处时间段(上午,下午,或者晚上),持续时间等。
行为特征 照片拍摄间隔的均值、中值和方差,用户移动速度等。
文本特征 由旅行路线中照片的文本标签组成的特征向量。
在实验中发现,文本特征是最有效的,其次是空间特征。空间特征对历史名胜和自然风光这两类的识别比较有效,而对其他类别的效果却不明显。
这是因为前两类路线对地点的依赖性非常大。还发现,如果使用时间和行为特征,算法会倾向于将所有的路线都分为本地类别,效果并不好。总之,使用文本和空间特征相结合的方法可以取得最好的结果。
旅行路线模式挖掘
使用文献[9]提出的TAS算法从路线数据中挖掘出频繁路线模式。TAS算法是对传统顺序模式挖掘算法的扩展,它可以输出元素之间的典型时间间隔。在找出这些频繁路线模式后,还为每个模式抽取出典型的文本标签。
标签抽取的算法基于TF-IDF方法,即假设在某一个路线模式中频繁出现,但不在其他路线模式中频繁出现的文本标签是具有代表性的标签。由于文本标签一般和地点非常相关,同时还应考虑它们的地理尺度问题,有些标签只在某些地理区域有代表性(称为本地标签),而另一些标签在全局都有代表性(称为全局标签)。在算法中,希望尽量避免输出全局标签,同时也避免输出所在城市名称等一些没有特别意义的标签。
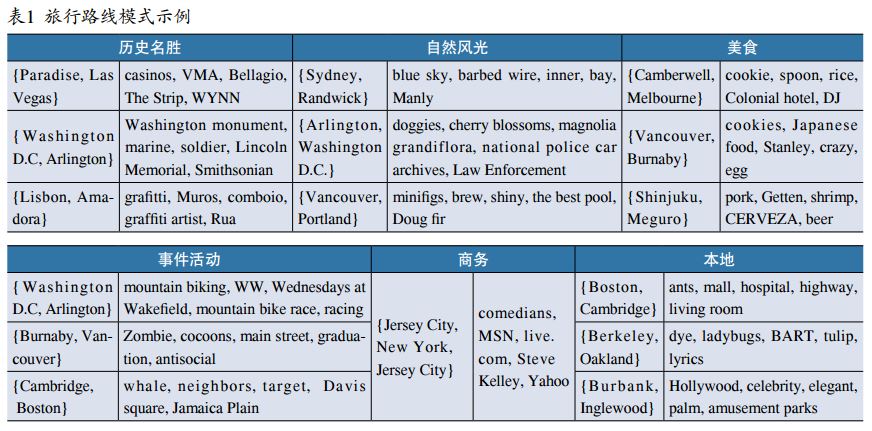
表1所示部分旅行路线模式。在表中可以看到,路线模式的典型标签可以提供很多额外的信息,一般也和其所在类别是一致的。例如在历史名胜类别中,发现的标签包括著名景点的名称(Bellagio和Washingtonmonument);在事件活动类别中,标签包括了事件的具体信息(Zombie和mountainbiking);而在本地类别中,输出的标签则代表了日常生活的信息(mall和BART)。有趣的是,即使对于同一个地点,在不同类别下也会找出不同的典型标签。例如从华盛顿到阿灵顿的路线,在历史名胜、自然风光和事件活动类别中的描述都是完全不同的。
结语
本文着重介绍了对普适计算技术未来发展的展望,以及微软亚洲研究院相关研究项目的进展。
通过移动设备,在人们日常使用的过程中收集来自物理世界的情境信息,获取知识,以帮助互联网上的其他应用。具体说,对带有地理标注的照片进行挖掘,详细说明了如何利用互联网上普遍存在的数据得到物理世界中的知识,例如城市中的地标性景点、不同旅行目的的典型路线等,这些知识对旅游应用都有很大帮助。
未来,我们还将针对更多类型的情景数据、个人行为识别(参见本期专题中杨强教授等撰写的《基于传感器数据的行为识别》一文)和知识集成等方向进行进一步研究。同时,传感器的数据收集也让人们开始担心隐私保护的问题。一旦这些数据使用不当,便很有可能会造成恶劣的后果。因此,设计系统时既要考虑保护人们的隐私,又要确保数据能正确使用。另外,长期的数据收集让移动设备产生了大量的能源消耗,与目前倡导的低碳生活宗旨不符。因此,需要在提供高服务质量的同时,尽可能地减少能源消耗。
参考文献:略。