和Google互补的搜索引擎Wolfram|Alpha

2009年5月18日,计算知识引擎Wolfram|Alpha正式上线。推出此产品的Wolfram(沃尔夫勒姆)研究公司是全球备受尊敬的软件公司之一,著名的科学计算软件Mathematica正是该公司的旗舰产品。早前,这家主营科学计算软件的公司将推出搜索引擎的消息一经传出,便引起了来自各方的关注与猜测,“Google杀手”、“智能搜索”、“语义网搜索”等称号纷纷被赋予这个尚处于内测阶段的产品。现在,Wolfram|Alpha对外开放已一月有余,在经过一段时间的亲身体验之后,人们对Wolfram|Alpha应该已经有了更客观深入的认识,因此是时候来澄清关于它的一些热点疑问了:Wolfram|Alpha与Google究竟是什么关系,Wolfram|Alpha自己是如何定位的?Wolfram|Alaph在多大程度上是语义网搜索呢?Wolfram|Alpha最终将走向何方,将如何盈利呢?为了弄清这些疑问,最好的办法是听听Wolfram公司自己人的看法,于是我们特地邀请到Wolfram研究公司中国区商务经理王翔,请他来谈一谈这些问题。

Wolfram|Alpha与Google是互补的
InfoQ中文站:为什么称Wolfram|Alpha为“计算知识搜索引擎(Computational Knowledge Search Engine)”?该名称说明什么?
王翔:我们称Wolfram|Alpha为“计算知识搜索引擎”,是因为它并非像普通搜索引擎那样搜索Web并返回链接,而是通过在内部知识库上做计算而得到结果的。
InfoQ中文站:Wolfram|Alpha总被拿来跟Google作比较。Google是一个面向公众用户的搜索引擎,请问Wolfram|Alpha是如何定位的呢?还有,关于Wolfram|Alpha跟Google的关系,您怎么看?
王翔:Wolfram|Alpha与Google是互补的。搜索引擎返回的是网页链接,而Wolfram|Alpha是利用其内部知识库与算法来针对特定问题计算结果的。
不过,Wolfram|Alpha也在其侧栏里提供了进行Web搜索的链接。
Wolfram|Alpha的用途及优势并不是如今的搜索查询。它允许用户提出全新的问题。基于以往在搜索方面的经验,我们预期,人们在认识到Wolfram|Alpha的能力后,很快就会习惯于做Wolfram|Alpha查询。另外,Wolfram|Alpha在使用模式上跟搜索也有所不同:人们会更加系统性地来使用它,比如人们会对同一个问题采用不同的参数。
InfoQ中文站:从技术上讲,Wolfram|Alpha与其他类似产品,比如Ask Jeeves、Google Base、Powerset以及著名的Cyc项目,有何不同呢?
王翔:Wolfram|Alpha跟他们不一样。Ask Jeeves和Powerset都是返回网页链接的搜索引擎,而Wolfram|Alpha提供通过计算得出的信息。
InfoQ中文站:都说Wolfram|Alpha比传统搜索引擎更为聪明,那么请问Wolfram|Alpha系统实际采用了多少AI技术?推理是如何进行的?结论或断言是怎么来的?另外,万一出现分歧怎么办?比方说,如何表达关于以色列/巴勒斯坦领土这种信息呢?
王翔:与其说Wolfram|Alpha是模拟人类的人工智能,还不如说它是一项工程产品。它的有些部分——尤其是语言理解方面——或许跟人类相似。但它的主要目标是进行导向性计算(directed computations),而不是提供一般性的智能。
Wolfram|Alpha运用已建立的科学模型或其他模型作为计算的基础。每当它进行新的计算时,它都会有效地得出新的结论。
关于你提到的数据冲突问题,我们会对数值数据和具体问题采取不同的办法。对于数值数据,Wolfram|Alpha的核审员(curators)通常会为其指定一个在计算过程中有效的值域。对于特定名词或术语的理解问题,就像你提到的以色列/巴勒斯坦领土问题,Wolfram|Alpha通常会提示用户选择他们乐意采纳的看法。
我们在自动化测试、专家评审以及核查(用以计算结果的)外部数据方面投入了巨大的精力。然而,由于我们的数据数以“T”计,因此难免仍存在一些错误。假如有人发现问题的话,欢迎向我们报告。
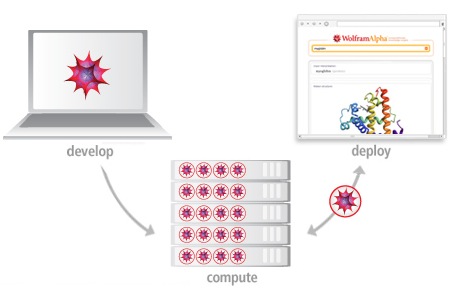
Wolfram|Alpha并没有直接采用语义网技术
InfoQ中文站:英国《卫报》编辑Charles Arthur在一篇文章中称Wolfram|Alpha为“语义网搜索(Semantic Web search)”。我想知道,Wolfram|Alpha是否确实是一种语义网搜索?你们是否在系统内部采用了一些语义网技术,或借鉴了语义网的思想?
王翔:Wolfram|Alpha并没有直接采用语义网技术。Wolfram|Alpha有自己的内部知识库,以及大量自有的内部语义及本体(ontology)。
InfoQ中文站:据称Wolfram|Alpha背后的数据容量超过10T之巨,而且这些数据都逐一打上了标签(tag)。我们很想知道,如此庞大的数据集采用的是什么样的数据模型?
王翔:Wolfram|Alpha里有数以T计的数据元素,它们借助于大量的提要(feed)而不断增长。
InfoQ中文站:那些经核审的数据目前只能被Wolfram|Alpha所用,但是它们对外部世界也同样有用。因此,你们是否有计划将这些数据对外开放,比如用RDF格式?或将Wolfram|Alpha的功能以Web服务的形式暴露出来?
王翔:Wolfram|Alpha里的大部分数据是在多个数据来源的基础上经计算得出的。在Wolfram|Alpha的结果页面底部,有一个“来源信息(Source information)”按钮,点击它可以看到数据来源与参考资料列表。
另外,有些数据已经是可直接为Mathematica用户所用的了(作为按需加载的计算数据)。此外,一个用于让用户从Wolfram|Alpha得到原始数据的API也正在开发之中。
InfoQ中文站:Wolfram|Alpha的原始数据是从哪里来的?这些数据来自各种不同的数据源,你们是如何处理潜在的异构与不一致性问题的呢?
王翔:数据来自许多不同来源,并且是经过Wolfram|Alpha团队的合并与核审的。为了核查Wolfram|Alpha的数据,我们采用了一系列自动化与手工的方法,包括统计、可视化、源交叉检查以及专家评审等。
InfoQ中文站:自然语言理解是Wolfram|Alpha系统中的重要一环,你们是否采用了一些特殊的、区别于现有其他系统的技术与策略呢?
王翔:Wolfram|Alpha在语言理解方面引入了许多新方法。他们大多跟传统的NLP不太一样,主要是因为Wolfram|Alpha需要处理语言片断,而不是语法完整的句子。
InfoQ中文站:我们注意到,Wolfram|Alpha跟“NKS(A New Kind of Science)”有些关系。能否请您解释一下NKS的理念是如何被应用到Wolfram|Alpha上的。
王翔:Wolfram|Alpha在概念与实践上均运用了NKS的“由简单的潜在规则产生丰富的复杂的行为”的理念。从许多方面来讲,Wolfram|Alpha是NKS的第一个“杀手级应用(killer app)”(详见Stephen Wolfram的博客文章:http://blog.wolfram.com/2009/05/14/7-years-of-nksand-its-first-killer-app/)。
Wolfram|Alpha如何盈利呢?
InfoQ中文站:Wolfram|Alpha将走向何方?越来越专业化,还是越来越一般化?
王翔:Wolfram|Alpha的远期目标是把所有系统化的知识变得可直接为人们所计算与访问。我们打算收集并核审所有客观数据;实现每一种已知的模型、方法及算法;并使之可以计算任何可被计算的东西。我们的目标是,在科学及其他知识系统化的成果的基础之上,提供一个可被人们信赖的、进行权威真实数据查询的数据源。
Wolfram|Alpha旨在把专家级的知识与能力赋予尽可能广泛的人们——无论什么专业或教育水平。我们的目标是成为这样一种知识引擎:它可以根据自由形式的输入,产生强大的结果,并以最清晰的方式展现这些结果。
Wolfram|Alpha是一个雄心勃勃的、长期的智力工程,我们计划通过若干年到几十年的努力来不断完善其功能。在世界级的团队及来自无数不同领域的顶级专家的帮助下,我们将缔造一个21世纪知识成就的重要里程碑。
InfoQ中文站:最后一个问题。Wolfram|Alpha是个好东西,这不错。但它如何盈利呢?你们关于它有什么样的商业计划?
王翔:我们正在为Wolfram|Alpha探索一系列的商业模式,包括与重要的第三方机构建立合作、寻求赞助以及未来推出专业版及企业版等。
专业版的细节现在还没最终定下来,但很可能会加入“上传自有数据到自己的服务器、并纳入(该上传用户的)计算范围”的功能,以及下载数据和图的功能,另外还会有更多的CPU时间用于计算。再进一步的话,企业版将可以在企业内部运行,并能够访问企业自己的数据库。例如,用户可以提出如“产品A/产品B的销售额”或者“John Smith的销售目标”等问题。
(注:本文根据和Wolfram研究公司中国区商务经理王翔的邮件采访整理而成。)