关于验证码(CAPTCHA,全自动区分计算机和人类的图灵测试)

区别人类和机器人的验证码在(CAPTCHA,全自动区分计算机和人类的图灵测试)在互联网上的第一次使用,是在雅虎公司的免费邮箱系统上。当时,作为互联网时代早期最重要的免费邮件提供商,雅虎一方面要解决用户们每天遇到的数以百计的垃圾邮件轰炸,另一方面,他们自己的免费邮箱,恰恰又是垃圾邮件的最爱——耗费无数资源所阻止的垃圾邮件,都来自于自己的服务器。
他们找到一位当时刚刚21岁的天才——卡内基梅隆大学的路易斯·冯·安(Luis Von Ahn)。他的设计很简单:计算机先是产生一个随机的字符串,然后用程序把这个字符串的图像进行随机的污染,扭曲,再显示给显示器前的人或者机器。凡是能够辨识这些字符的,即为人类。在当时的技术环境下,这一设计能够非常高效地区分真实用户和机器人,也就很快的在大部分网站上成为标准配置。但当全世界数以十亿计的人每天都会浪费几秒钟的时间参与辨认文字这一简单活动的时候,路易斯·冯·安开始思考,其中浪费的人脑智力是否能得到更好的应用呢? 他深思熟虑的结果就是第二代验证码reCAPTCHA。
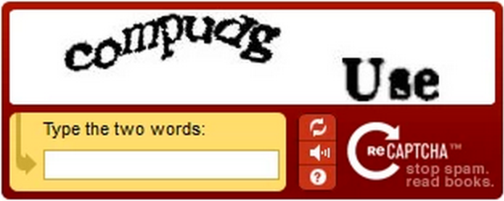
reCAPTCHA 能够抓取古旧书籍中因年代久远、略有破损或污染而难以被计算机识别的单词,并利用人类对这些单词的识别能力区分机器和真实用户。具体来说,reCAPTCHA系统会将一个古籍中电脑无法识别的未知单词和一个已经被正确识别的已知单词组合成一组验证码。如果用户答对了已知单词,那么系统认为他识别的未知单词也是对的。如果有两个及以上的真实用户在reCAPTCHA中回答了同一结果,这一未知单词就会被放入已知单词数据中。周而复始,一本古籍中难以被计算机识别的单词,很快就会在网友不经意的帮助下被识别和翻译出来。
虽然用户每次只需要识别一个单词,但因为reCAPTCHA应用广泛,这一系统能很快的完成古籍的电子化。reCAPTCHA在2014年前的口号就是“阻止骚扰,读更多书”。和光学识别技术(OCR)一起,reCAPTCHA系统在数月之内完成了《纽约时报》130年存档的数字化——若由人工完成,这一工程本可能会花费数年时间。
路易斯·冯·安主导的reCAPTCHA在2009年被谷歌收购。之后国外陆续有一些网站的 reCAPTCHA 的验证码内容发生了变化,所显示的不再仅仅是古籍文字,而是还有照片——照片的一侧显示的是大家熟悉的扭曲的文字,另一侧则是模糊的数字,这些数字无疑就是街道地址。谷歌的一位发言人介绍说,新的reCAPTCHA系统会抓取谷歌街景中的街道地址、名称,甚至交通标志:一方面,这样加大了恶意程序利用人工智能技术识别验证码的难度;另外一方面,可以利用reCAPTCHA向谷歌地图里添加商铺地址和位置等有用信息,让普通人受益。
技术的演进让传统的验证码越来越容易被恶意程序识别,谷歌于2014年推出了利用用户行为模式和用户历史信息等进行分析的noCAPTCHA系统。用户只需要勾选一个“我不是机器人”的复选框,系统就能完成对用户的识别;只有在少数系统拿不准的时候,用户才会被要求填写识别码。
在验证码演进中,路易斯·冯·安和谷歌的价值取向很清晰:在能够有效区分真实用户和机器人的前提下,尽量减少让用户承担的不必要的成本,没有验证码最好;如果出于技术需要,必须要求用户填写验证码,这个过程应该尽量造福普通人。