Internet Archive:记录那些被遗忘的互联网

他们试图备份整个互联网。
在 Martin Luther King, Jr 的维基百科词条下面,附注着三百多条脚注,其中包括 66 本书籍引用。
这是人们信赖维基百科的原因,几乎每一则词条的每一处描述都有迹可循,查阅者可以通过参考资料检验词条文本的准确性。
不过就算是维基百科这样的互联网百科全书,它能记录的也非常有限。《纽约客》一篇题为 Can the Internet be archived?的文章中曾经写道,「网络永远生活在当下。它虚幻、短暂、不稳定、不可靠。有时候你想要访问的网页却指向了 404… 有时候你想要查询的页面已经被更新后的内容覆盖——这更麻烦,因为网页不会告诉你,你看到的内容压根儿不是你想查询的内容。」
那么,有没有办法能够找到那些 404 或者修改前的网络内容呢?
备份互联网
有人试图备份整个互联网。
1996 年,因为担心网络上的信息不能像印刷在书籍里一样被永恒地保存下来,布鲁斯特·卡利(Brewster Kahle)创立了公益性质网站 Internet Archive。
很多人将 Internet Archive 定义为最伟大的搜索网站。Kahle 开发的搜索工具 Wayback Machine 定期收录和抓取全球网站的信息,并进行保存。Wayback Machine 的工作也有主次之分,对于不同的网站,收录的数量和频次也不相同。
截止到现在,Internet Archive 已经保存了 3300 亿网页和页面快照,而 Internet Archive 的伟大在于,除此之外,这个庞大的档案馆还记录了 2000 万册图书和文本,850 万份音频和视频、300 万幅图像和 20 万个软件程序。
总而言之,Internet Archive 想做的是让信息获取更加简单和准确。最近,Internet Archive 和维基百科联手做了一件事情,让维基百科更靠谱了。Internet Archive 已经将维基百科脚注中 13 万条书籍引用定向链接到 Internet Archive 5 万本(覆盖英语、希腊语和阿拉伯语)完成过数字化扫描,且对公众公开的书籍。查阅者可以通过点击脚注的页码,查看被引用部分的两页上下文预览。
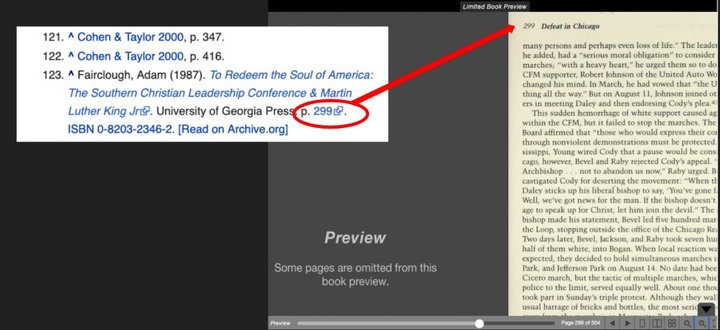
▲查阅者可以通过点击脚注的页码,查看被引用部分的两页上下文预览 | Internet Archive
网络图书馆
上述《纽约客》文章中说,「脚注是人类文明史上的一个里程碑,发明和传播它花了几个世纪的时间,摧毁它仅仅用了几年。比如过去,书籍和论文的脚注能让你准确了解到额外的信息,以及信息的来源。现在,当一切搬到互联网上,你仍然可以通过点击脚注的链接获取更多信息,只不过你不知道兴许哪一天链接就失效了。」
2016 年 10 月,维基百科和 Internet Archive 宣布合作解决失效链接问题,Wayback Machine 主管 Mark Graham 开发的 InternetArchive Bot 自动扫描维基百科脚注的失效链接,并自动将失效链接连接到 Wayback Machine 保存的页面。「我们编辑了 1400 万链接,超过 1100 万链接到 Internet Archive。」Graham 说到。
链接书籍的工作与之类似,但是更具有挑战性。Graham 解释说,并非所有书籍都有 ISBN 编码,也并非所有脚注都参考了正确引用格式,标注了具体的页码。
Internet Archive 称自己为网络图书馆。不少线下图书馆也会对书籍数字化之后借阅给用户。当你对某一本引用的书籍感兴趣,就可以问 Internet Archive 借阅到电子版。
Internet Archive 从 2005 年开始着手书籍数字化的工作,它的「馆藏」里已经有了 380 万本。目前 Internet Archive 在全球设了 22 个工作点,每天有 100 位员工以每天 1000 本的速度加快扫描工作,即便这样还有数百万本书排队等候。
数字时代,人们与书本的距离越来越远。Kahle 称,「我们希望从维基百科开始,通过将书籍编织进互联网的方式,将读者与书籍连接起来。」
互联网档案馆
80、90 后的青春可能随着某天天涯和豆瓣的关闭而停驻,Facebook 成立以来也不过十几年光景。互联网加速了信息的传播和迭代,相应地人们遗忘得也越快。但是在 Internet Archive,念旧的人可以看到当时的热点话题「制造机」天涯社区,以及现在看来有些「非主流」的新浪微博首页快照。

▲Internet Archive 保存的天涯和新浪微博的快照 | Internet Archive
正如《纽约客》评论道,几乎可以肯定,如果哪些东西没有被网页时光机(Wayback Machine)收录,它们等于从来没有存在过。
2014 年 7 月 17 日,马来西亚一架波音 777 客机起飞后不到三小时在乌克兰坠毁。乌克兰反对派指挥官 Strelkov 在俄罗斯社交媒体 VKontakte 发布一条消息,「我们刚刚击落一架飞机,一架 AN-26。」这则帖子包含了飞机残骸的视频链接,看起来像是波音 777,随后被删除。第二天,这则帖子被收录到 Wayback Machine,Internet Archive 在 Facebook 发帖称,「这就是我们存在的意义。」
正如《金融时报》评论,在一个虚假信息,极端主义内容被迅速创造和传播,社交媒体信息不断迭代和更新的时代里,能够记录「谁说了什么」,「何时说了什么」而且内容不可更改的重要性被放大了。通过 Internet Archive 对不同时期的历史信息进行研究,是它更大的价值所在。比如在特朗普当选之后,Internet Archive 收集了包括特朗普就职前的 6000 多段视频帮助人们辨别和核实虚假信息。
然而,想要建立全球化的互联网档案馆不太容易,部分原因在于各个国家在法定送存、版权、隐私等法律问题上无法统一。今年年初,英国作家协会(The Society of Authors)表示 Internet Archive 做法涉嫌侵权——在英国所有的书籍扫描和借阅行为必须得到版权所有者的授权,且每一次借阅能为作者带来 8.52 便士的公共出借报酬。英国作家协会指摘 Internet Archive 没有得到作者的许可,同时没有支付任何报酬。
不久之后,一份由全美作家联盟(NationalWritersUnion)发布,其余 36 个组织(包括 The Society of Authors)共同签署的文件,谴责 Internet Archive 和合作图书馆扫描和分发电子书的行为。虽然 Internet Archive 解释他签署了 CDL(controlled digital lending)协议——在没有获得版权所有者的许可下,允许图书馆数字化印刷书籍,并借出给用户。前提是规定借出数量和时间上限,并且基于合理使用(Fair use)制度,借出数量必须与数字化前实体书籍数目一致(一旦一本实体书被借出,它的对应电子版本则不能借出,反之亦然。)
法律跟不上技术迭代的步伐,就如同许多敢为人先者一样,Internet Archive 身处在资源共享和版权至上的夹缝之中。

▲互联网档案馆创始人 Brewster Kahle | 维基百科
「在中国互联网的古代,人们不仅只是使用互联网,那时候的人们参与建设互联网… 比如说前往维基百科编纂词条,管理内容。在中文互联网世界里,人们去豆瓣网增添电影、书籍、音乐专辑的条目,便于其他网友标注、收藏和评论。」网络写手和菜头曾如此写道。
这或许和 Internet Archive 想要打造的互联网世界相似,用 Graham 的话说,Internet Archive 希望普及所有知识。Kahle 表示,尽管 Internet Archive 扎根在旧金山,但是与今天的硅谷共同点少之又少。他希望所有技术的「遗产」最后不是掌握在少数人手中,「我喜欢很多人都能赢的感觉。」